Clusters of unknowns refinement
The EUs represent the most critical of our cluster categories since we expected them to be clusters of entirely novel/unknown ORFs. To ensure their novelty, we further processed them searching eventual remote homologies to annotated proteins.
Methods
We screened the EUs using HHblits [1] against the Uniclust database (release 30_2017_10) using the HMM comparison method since it is currently considered one of the most sensitive approaches for homology detection [2]. The results were parsed using a probability threshold of 90% and then processed with the same system used for the classification of the unknowns to retrieve the hits annotated to hypothetical or characterised proteins. The firsts were then moved to the class of GU and the second to the KWP. The clusters with no matches, i.e., no homologies, represented the refined set of EU.
Results
We found that the 61% of the EUs have/show a remote homology to a Uniclust entry/protein. Of the matching clusters, 171,183 resulted in distant homologs of hypothetical proteins and were moved to the GUs category, whereas 38,333 clusters matched characterized proteins and were transferred to the KWPs set. Hence, after this refinement step, the number of EUs has reduced to 135,829 clusters, and the whole dataset results now dominated by the GU clusters.
Unknown refinement steps in terms of number of clusters.
| K | KWP | GU | EU | |
|---|---|---|---|---|
| Clusters (pre-EUs_refinement) | 912,551 | 753,718 | 928,643 | 345,345 |
| EUs refinement | - | +38,333 | +171,183 | -209,516 |
| Clusters (post-EUs_refinement) | 912,551 (31%) | 792,051 (27%) | 1,099,826 (37%) | 135,829 (5%) |
First step refined cluster categories and ORFs content.
| K | KWP | GU | EU | Total | |
|---|---|---|---|---|---|
| Clusters | 912,551 | 792,051 | 1,099,826 | 135,829 | 2,940,257 |
| ORFs | 164,720,321 | 39,188,198 | 52,892,578 | 3,341,257 | 260,142,354 |
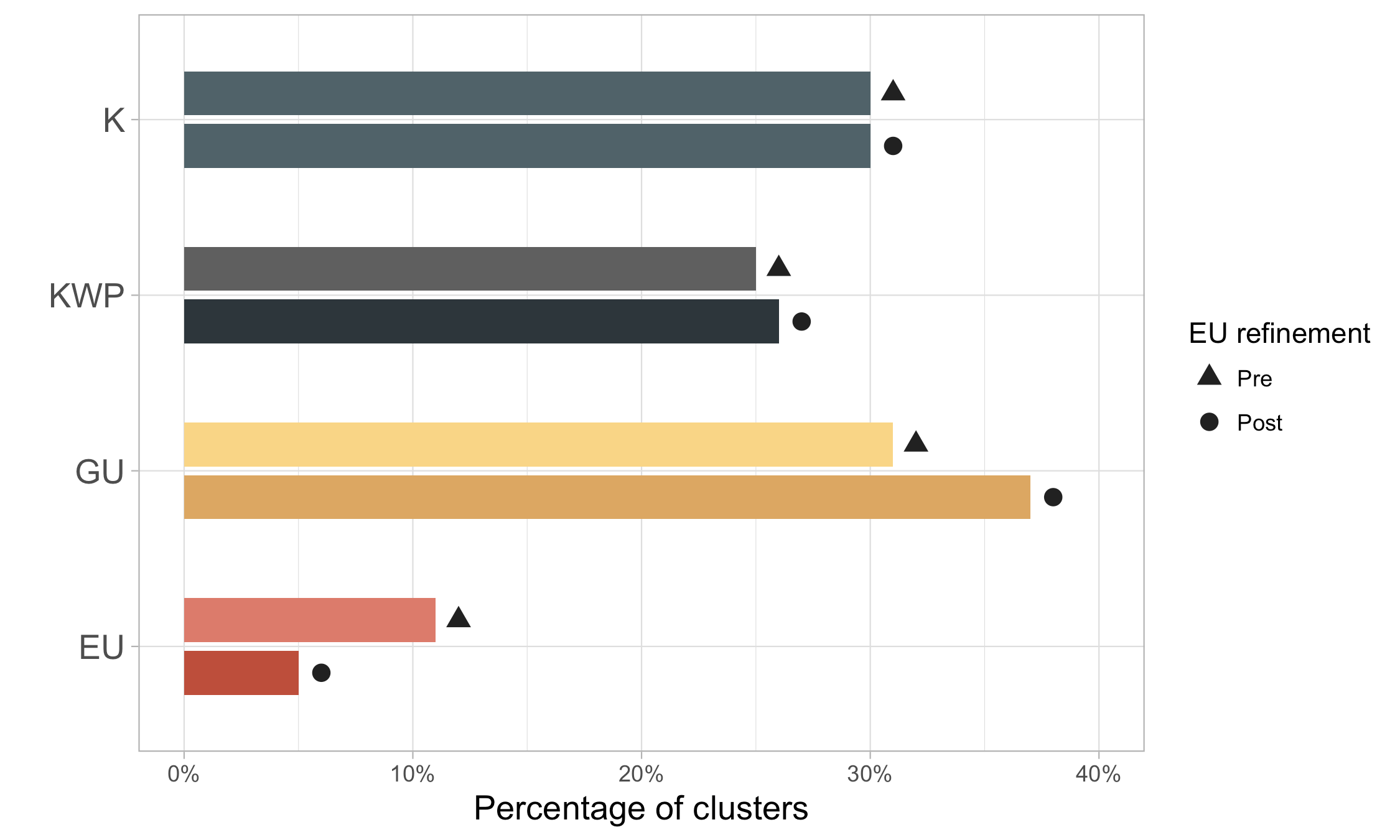
Percentage of clusters in the different category before and after the refinement.
Clusters of knowns refinement
The KWPs set may contain clusters with remote homologies to Pfam protein domains.
Methods
We screened the KWPs using HHblits [1] against the Pfam database (version 31, http://wwwuser.gwdg.de/~compbiol/data/hhsuite/databases/hhsuite_dbs/pfamA_31.0.tgz) using the HMM comparison method since it is currently considered one of the most sensitive approaches for homology detection [2]. The results were parsed using a probability threshold of 90%, a target coverage ≥ 0.6, and we selected only non overlapping domains. The KWPs returning remote homologies to Pfam domain of known function were then moved to the Ks set, and those showing remote homologies to DUFs to the GUs.
Results
We found that about 20% of the KWP clusters show a remote homology to Pfam protein domains. Of the matching clusters, 137,615 (86%) resulted distant homologs of Pfam domain of known function and were moved to the Ks category, and 21,983 (14%) clusters matched DUFs and were transferred to the GUs set. Hence, after this refinement step, the number of KWPs was reduced to 632,453 clusters.
Refinement of the K’s DAs. Updating the Ks implies also updating the cluster representative DAs. Considering both Pfam domain of known function and DUFs we now have 32,616 original DAs (29,341 with reduced names and 26,272 with reduced names and contracted repeats). The Ks DAs are now 29,379 (23,365 reduced), composed of 19,927 multi-domain and 9,453 mono-domain annotations. The clusters with multi-domain annotations are 133,253, and those with mono-domain annotations 916,914.
Known refinement steps in terms of number of clusters.
| K | KWP | GU | EU | |
|---|---|---|---|---|
| Clusters (pre-KWPs_refinement) | 912,551 | 792,051 | 1,099,826 | 135,829 |
| KWPs refinement | +137,615 | -159,598 | +21,983 | - |
| Clusters (post-KWPs_refinement) | 1,050,166 (36%) | 632,453 (21%) | 1,121,809 (38%) | 135,829 (5%) |
Refined cluster categories and ORFs content.
| K | KWP | GU | EU | Total | |
|---|---|---|---|---|---|
| Clusters | 1,050,166 | 632,453 | 1,121,809 | 135,829 | 2,940,257 |
| ORFs | 172,147,128 | 30,601,694 | 54,052,275 | 3,341,257 | 260,142,354 |
An overview of the metagenomic cluster categories, including additional information about their taxonomy, level of darkness, completeness and set of HQ-clusters can e found here.
Finalization of the cluster categories
After the refinement we combined together the annotations for the categories with annotated clusters (K,KWP and GU). We also created two summary files: one mapping all the clusters with the respective category, “cluster_ids_categ.tsv” and one with an additional field containing the cluster ORFs: “cluster_ids_categ_orfs.tsv”. The commands used to gather this information are stored in the script clu_categ_summary.sh.
In the end, we build an HH-suite database (ffindex dbs) for each category, using the script categ_ffindex_files.sh.
Refinement of the unknown:
The main script, unkn_refinement.sh, takes as input the EUs cluster ids, searches them against the Uniclust HMM DB, and parse the results through the codes hh_parser.sh and hh_reader.py. The output are updated sets of cluster ids reported in a file for each category. For more detailed info check the README.md file.
Refinement of the known:
The main script, known_refinement.sh, takes as input the KWPs cluster ids, searches them against the Pfam HMM DB, through the code hhparse_kwp.sh, and then parse the results. The output are updated sets of cluster ids divided in a file for each category. For more detailed info check the README.md file.
[1] M. Remmert, A. Biegert, A. Hauser, and J. Söding, “HHblits: lightning-fast iterative protein sequence searching by HMM-HMM alignment.,” Nat Methods, Nov. 2011.
[2] B. Lobb, D. A. Kurtz, G. Moreno-Hagelsieb, and A. C. Doxey, “Remote homology and the functions of metagenomic dark matter.,” Frontiers in genetics, vol. 6, p. 234, Jul. 2015.